ClipTraining
Semantic video search infrastructure powered by AI

Overview
ClipTraining is an AI-powered search infrastructure that transforms video libraries into a queryable knowledge base.
Users can search using natural language and retrieve exact moments in videos (minute + second) where the answer appears.
The Problem
Video content is inherently difficult to search.
- No semantic understanding
- Metadata is incomplete or inconsistent
- Users must manually scrub through videos
- Scaling search across thousands of clips is costly
The Solution
I designed and implemented an end-to-end pipeline that:
- Transcribes videos with timestamps
- Converts content into vector embeddings
- Enables semantic search via natural language
- Returns precise video segments
System Overview
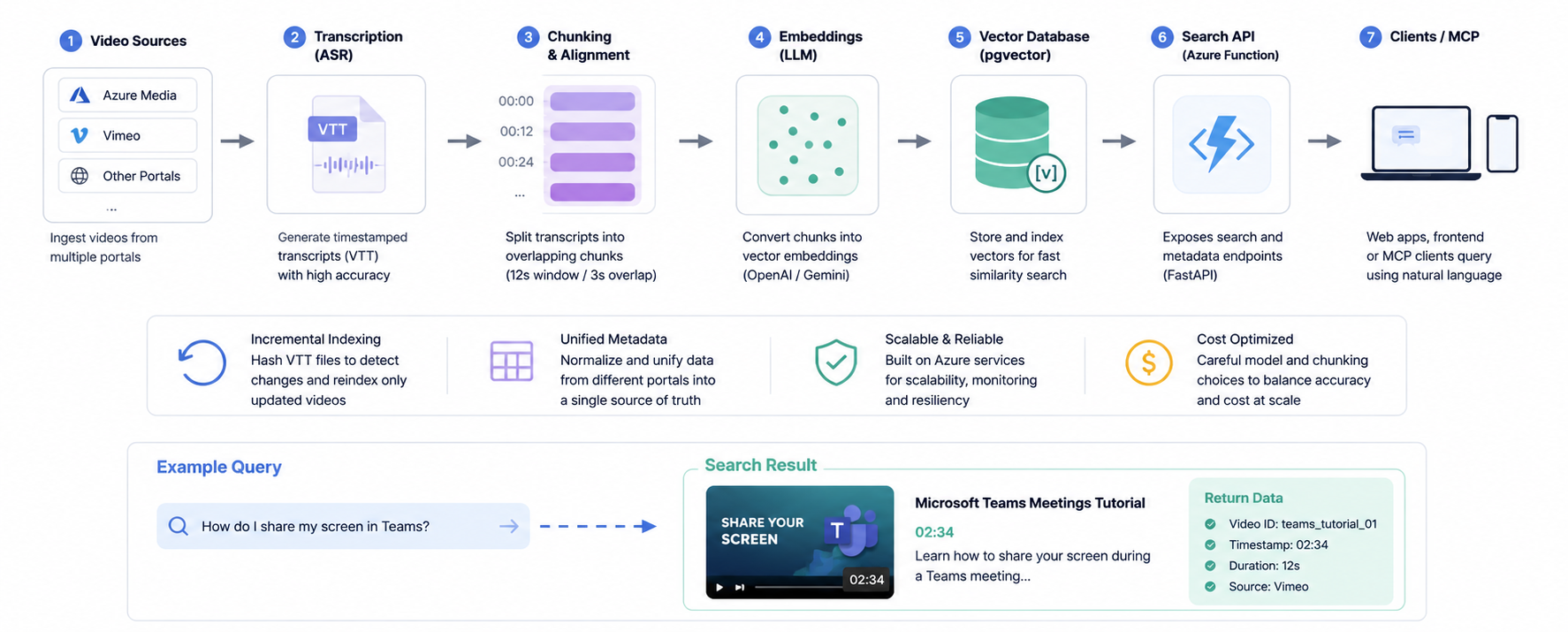
Key Contributions
Transcription & Time Alignment

- Evaluated multiple ASR providers (Whisper, AssemblyAI, GCP, AWS)
- Generated accurate timestamped transcripts
- Improved alignment for precise segment retrieval
Metadata Enrichment

- Identified gaps in existing metadata
- Generated contextual metadata using LLMs
- Improved search relevance and discoverability
Chunking Strategy (A/B Testing)

- Tested multiple chunk sizes and overlaps
- Evaluated impact on retrieval accuracy and latency
- Selected optimal configuration: 12s window / 3s overlap
Embeddings & Retrieval

- Benchmarked OpenAI vs Gemini embeddings
- Optimized for semantic accuracy vs performance tradeoffs
- Enabled similarity-based search beyond keywords
Vector Database Architecture

- Evaluated Pinecone, FAISS, ChromaDB, and pgvector
- Implemented scalable storage and retrieval layer
- Designed for fast similarity search across large datasets
Incremental Indexing
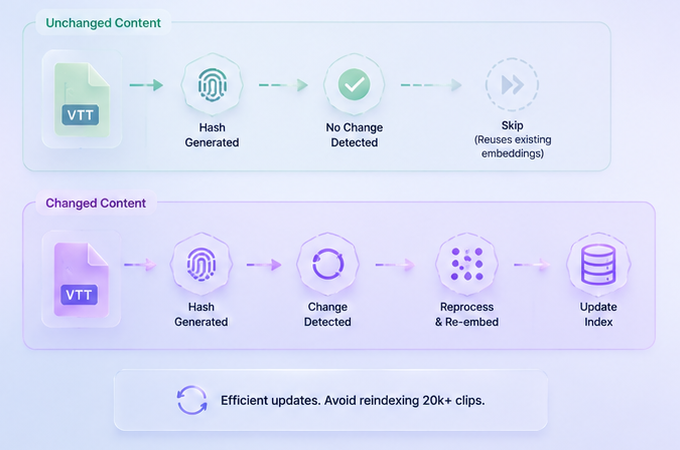
- Avoided full reprocessing of ~20k video clips
- Implemented hashing strategy on VTT files
- Re-index only modified content
Search API (Production Deployment)
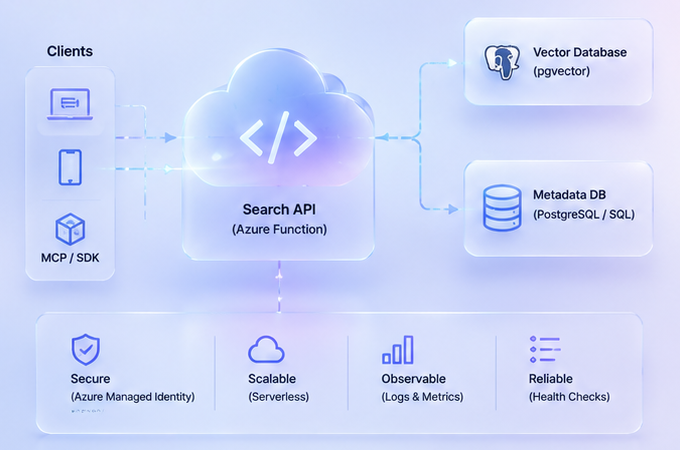
- Built FastAPI service deployed on Azure Functions
- Endpoints:
/search/index/health
- Integrated with PostgreSQL (pgvector) and Azure infrastructure
Cost Optimization
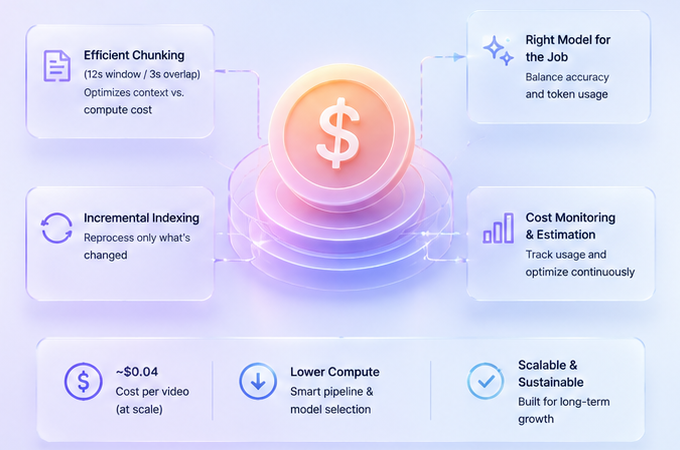
- Modeled API costs for transcription, embeddings, and metadata
- Identified low per-video cost (~$0.04 at scale)
- Balanced accuracy vs compute efficiency
Example Output
Query: “How do I share my screen in Teams?”
Result:
- Video: Teams Meetings Tutorial
- Timestamp: 02:34
- Segment: “Click the share button in the meeting controls…”
Outcome
- Production-ready semantic video search system
- Scales to ~20k video clips
- Enables conversational and API-based search experiences
- Ready for frontend integration and enterprise use
Key Learnings
- Chunking strategy has a major impact on retrieval quality
- Metadata + semantic search (hybrid) significantly improves precision
- Cost modeling is critical for scaling AI systems
- Incremental pipelines are essential for real-world deployments